야! 너도 할 수 있어, N+1 해결
안녕하세요, 트렌비 Resale 개발팀의 포비입니다.
먼저 리세일 팀에 대해서 간략하게 설명해 드리겠습니다.
리세일 팀은 고객이 판매하고자 하는 상품을 받아 견적을 내고, 판매가 이루어지도록 하는 업무를 담당하고 있는데요.
리세일 개발팀은 고객 자신이 소유한 상품을 판매할 수 있는 서비스와 이를 운영하는데 필요한 백오피스를 담당하고 있습니다.
이 글은 ORM(Object Relational Mapping)을 구현한 JPA를 다룬다면 한 번쯤은 겪을 수밖에 없는 N+1 문제에 대해 집중적으로 다뤄보려 합니다.
겪었던 문제
백오피스는 그 특성상 목록 조회를 주로 사용합니다. 그러나 이 백오피스의 특정 조회 화면에서 100건을 읽어오는데 2초 이상 오래 걸렸고, 이 느린 조회 때문에 백오피스 사용자가 업무를 처리하는 데 큰 어려움을 겪고 있었습니다.
1. N+1이 뭔데?
‘주문’과 ‘주문 아이템’, ‘상품’으로 간단히 예를 들어보겠습니다.
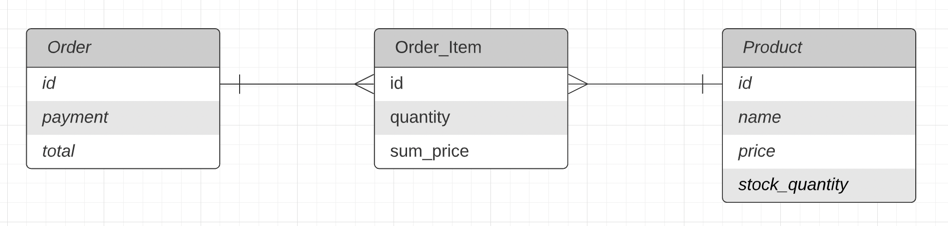
[Order]
@Getter
@Builder
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@AllArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
@Table(name = "orders")
public class Order {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Enumerated(EnumType.STRING)
private Payment payment;
private int total;
}
[OrderItem]
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class OrderItem {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "order_id")
private Order order;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "product_id")
private Product product;
private int quantity;
private int sumPrice;
public OrderItem(Order order, Product product, int quantity) {
this.order = order;
this.product = product;
this.quantity = quantity;
}
public void calculateSumPrice() {
sumPrice = product.getPrice() * quantity;
}
}
[Product]
@Getter
@Builder
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@AllArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class Product {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private int price;
private int stockQuantity;
}
도메인과 엔티티가 정의되었으니, 다음 시나리오를 가정해봅시다.
“[주문 아이템]이 어느 [주문]에 포함되어있고, 어떤 [상품]을 가졌는지 조회합니다.”
@Repository
@RequiredArgsConstructor
public class OrderItemQuerydslRepositoryImpl implements OrderItemQuerydslRepository {
private final JPAQueryFactory factory;
@Override
public List<OrderItem> getOrderItems() {
return factory
.selectFrom(orderItem)
.join(orderItem.order, order)
.join(orderItem.product, product)
.limit(1000)
.fetch();
}
}
겉으로 보기에는 문제가 없어 보입니다. 하지만 getOrderItems()가 호출되고 나면 저희가 의도치 않은 무수한 쿼리들을 보실 수 있습니다.
어쩌면 최악의 경우, 주문을 가져오는 select 1,000번, 상품을 가져오는 select 1,000번이 호출될 수 있습니다.
즉, 저희는 주문 아이템 1,000개를 조회하는 1회의 쿼리를 했을 뿐인데, 뜬금없이 별도의 select 쿼리가 발생한 것입니다.
이를 N+1 문제라 합니다.
2. N+1이 왜 생기는데?
N+1 문제는 MyBatis, JdbcTemplate 등 Mapper를 사용해 JDBC를 처리할 때는 없는 현상입니다.
그러나 JPA를 사용하는 경우에는 N+1 문제가 발생할 수 있습니다. 이는 JPA의 프록시(Proxy)를 이해하면 왜 발생하는지 알 수 있습니다. 다만, 프록시의 내용이 많고 난이도가 있으므로 상세하게 이해하는데 어려운 부분이 존재할 수 있습니다.
여기선 ‘프록시’를 간단하게 알아보겠습니다.
프록시 (Proxy)
먼저, ‘프록시’를 이해하기 위해 다음 하나의 질문에서 시작해보도록 하겠습니다.
Q. [주문 아이템]을 조회하는데 [주문]과 [상품]을 항상 함께 조회해야 할까?
답은 “No!” 입니다.
만약 그렇다면 우리는 JPA에게 매력을 느끼지 못할 것입니다. 제약이 걸려있으니까요. 하지만 위의 Entity에서 볼 수 있듯이, OrderItem은 Product와 Order를 멤버로 갖고 있습니다. 이때 OrderItem만 조회하고 싶다해서 order와 product에 null을 넣을 수 있을까요? 이는 완전히 다른 문제입니다. 해당 주문 아이템이 어떤 주문과 어떤 상품과도 연관이 없다는 것을 의미하니까요.
‘그럼 도대체 주문 아이템만 조회하려면 어떻게 하나요?’ 라는 궁금증이 생깁니다. 여기서 등장하는 것이 프록시입니다. OrderItem의 product와 order를 프록시로 가져오는 것입니다.
[프록시의 특징]
- 실제 클래스를 상속받아서 만들어집니다.
- 실제 클래스와 겉모양이 같습니다.
- 사용하는 입장에서 진짜 엔티티 객체인지, 프록시 객체인지 구분하지 않고 사용하면 됩니다.
- 프록시 객체는 실제 객체의 참조(target)를 보관합니다.
- 프록시 객체를 호출하면 프록시 객체는 실제 객체의 메서드를 호출합니다.
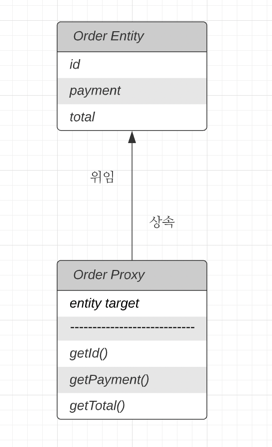
즉, OrderItem만 조회하고 싶다면 OrderItem에 연관된 엔티티인 Product와 Order는 프록시로 조회하면 됩니다. 여기서 프록시는 빈 깡통이라고 보면 됩니다. 실제 값이 들어있지 않습니다.
프록시를 초기화하는 방법
프록시로 받아왔지만, 이것을 실제 엔티티처럼 사용할 수 있어야 합니다. 하지만 값이 없는 깡통에 어떻게 값을 가져올까요?
간단하게 프록시의 메서드를 호출하면 프록시를 초기화할 수 있습니다. 이때 초기화하기 위해 데이터베이스에 조회를 하게 됩니다.
OrderItem orderItem = orderItemRepository.findById(1L).get();
/**
* "Order 프록시 강제 초기화"
* DB에 select 쿼리를 날려 해당 Order 엔티티의 값을 가져옵니다.
* 즉, 총 2회의 select 쿼리가 발생합니다.
* */
orderItem.getOrder.getPayment();
N+1이 발생하는 이유
앞에서 길게 설명해 드렸지만, 결국 N+1이 발생하는 이유는 프록시 초기화가 일어났기 때문입니다. (사실 지연로딩과 즉시로딩의 개념까지 알아야 하지만, 다른 글에서 깊게 살펴보겠습니다.)
아까 위에서 호출했던 OrderItemRepository의 getOrderItems() 메서드를 다시 한번 보겠습니다.
public List<OrderItem> getOrderItems() {
return factory
.selectFrom(orderItem)
.join(orderItem.order, order)
.join(orderItem.product, product)
.limit(1000)
.fetch();
}
여기서 OrderItem을 조회했는데 Order와 Product를 Proxy로 가져왔고, 이후 이를 강제로 초기화했다고 볼 수 있겠습니다.
그런데 분명히 join을 걸어서 가져왔는데 왜 프록시로 가져왔을까요? 이는 쿼리를 보며 이해해보도록 하겠습니다.
select
orderitem0_.id as id1_0_,
orderitem0_.order_id as order_id4_0_,
orderitem0_.product_id as product_5_0_,
orderitem0_.quantity as quantity2_0_,
orderitem0_.sum_price as sum_pric3_0_
from
order_item orderitem0_
inner join
orders order1_
on orderitem0_.order_id=order1_.id
inner join
product product2_
on orderitem0_.product_id=product2_.id limit ?
그렇습니다. join은 했지만, select를 안했기 때문에 order와 product를 프록시로 가져온 것입니다.
3. 그래서 N+1 문제의 영향이 뭔데?
N+1로 인한 문제는 짐작하고 계실지도 모르겠습니다. 바로 ‘성능‘과 직결됩니다.
주문 아이템 1,000개의 데이터를 가져오는데 1 번의 쿼리로 가능하지만, 최악의 경우 2,000번의 쿼리(주문 1,000번, 상품 1,000번)가 더 발생하므로 불필요한 리소스가 사용되는 것은 물론, 시간도 훨씬 많이 소요됩니다. 이로 인해 담당한 서비스의 장애로 이어지게 됩니다.
성능도 성능이지만 우리가 의도치 않은 SQL이 호출되고 있으니 만족스럽지 않을 것입니다.
우리는 반드시 이를 해결하고 코드를 제어할 수 있어야 합니다.
4. 어떻게 해결하는데?
해결하는 방법은 페치 조인(fetch join)과 DTO 조회가 있습니다. 이 글에서는 비교적 간단한 페치 조인으로 풀어보겠습니다.
페치 조인 (fetch join)
- SQL에서 사용하는 조인의 종류가 아닙니다.
- JPQL에서 성능 최적화를 위해 제공해주는 기능입니다.
- 연관된 Entity나 Collection을 SQL 1번에 함께 조회하는 기능입니다.
- Inner Join과 Left Join 모두 가능합니다.
페치조인은 JPA를 사용하기 위해서 반드시 숙지해야 할 스킬 중 하나입니다. 사용법은 다음과 같습니다.
/* JPQL */
String JPQL = "select oi from OrderItem oi join fetch oi.order o";
/* SQL */
SELECT
oi.*, o.*
FROM
OrderItem oi
INNER JOIN
Orders o on o.id = oi.order_id
페치 조인을 소개해드렸으니, 위에서 발생한 N+1 문제를
- JPQL
- Querydsl
- Spring Data JPA
을 사용할 때 각각 어떻게 페치 조인 하는지 알아보겠습니다.
JPQL
@Override
public List<OrderItem> getOrderItemsJPQL() {
String query = "select oi from OrderItem oi "
+ "join fetch oi.order o "
+ "join fetch oi.product p";
return em.createQuery(query, OrderItem.class)
.setMaxResults(1000)
.getResultList();
}
Querydsl
@Override
public List<OrderItem> getOrderItems() {
return factory
.selectFrom(orderItem)
.join(orderItem.order, order).fetchJoin()
.join(orderItem.product, product).fetchJoin()
.limit(1000)
.fetch();
}
Spring Data JPA
@Query("select oi "
+ "from OrderItem oi "
+ "join fetch oi.order o "
+ "join fetch oi.product p")
List<OrderItem> getOrderItemsDataJPA(Pageable pageable);
Spring Data JPA을 사용해보셨다면 ‘어? 네임드 쿼리로 사용하면 될 것 같은데?’ 라고 생각하실 수 있을 것 같습니다.
맞습니다. Spring Data JPA를 사용하는 이유는 JPQL을 직접 작성하지 않고 메서드 명으로 쿼리를 작성하는 namedQuery를 사용하려는 이유도 있습니다.
그렇다면 네임드 쿼리에서는 어떻게 조인을 할 수 있을까요? 바로 @EntityGraph 라는 어노테이션을 통해 간단하게 페치 조인을 구현할 수 있습니다.
다만, @EntityGraph로는 left join만 구현할 수 있으므로, inner join이 필요하다면 위처럼 직접 JPQL로 구현해야 합니다.
@EntityGraph(attributePaths = {"product", "order"})
List<OrderItem> getOrderItemsBy(Pageable pageable);
5. Before / After
이제 N+1 문제를 해결함으로써 얼마큼 성능 향상이 되었는지 수치(소요 시간)를 보도록 하겠습니다.
모든 케이스를 나열하기보다 가장 극적이게 개선된 부분을 강조하자면 다음과 같습니다.
[데이터 엑셀 조회]
엔티티 A
- 연관된 엔티티
- B
- C
- D
- E
- F
5개의 테이블을 조인해서 데이터 목록을 가져오는 부분에서 N+1 문제가 발생하였습니다. 최악의 경우 1,000건의 데이터를 조회하는데 5,001번의 쿼리가 발생할 수 있습니다.
Before
약 13,000ms ~ 45,900ms
After
약 1,300ms ~ 1,400ms
6. 마치며
JPA를 사용하며 한 번쯤은 마주하게 되는 N+1 문제를 페치 조인을 통해 해결하고, 성능 최적화를 하였습니다. 위의 페치 조인과 더불어 DTO 조회 해결 방법도 있습니다. 이는 페치 조인으로도 해결이 안 되면 시도해보시는 것도 좋은 방안입니다.
추가로 지연로딩(LAZY)과 즉시로딩(EAGER)의 개념도 반드시 알아야 N+1 문제를 완벽하게 제어할 수 있다고 말씀드릴 수 있겠습니다.
저는 개인적으로 지연로딩을 기본으로 설정하고 그때그때 페치 조인을 사용하는 것을 선호합니다.
긴 글 읽어주셔서 감사드립니다.