백오피스 엑셀 다운로드 속도 개선하기
안녕하세요, 트렌비 가든 개발팀의 도리입니다.
저희 가든 팀에서는 내부 직원들이 사용하는 백오피스(Back Office)를 개발하고 있습니다.
백오피스를 개발하다 보면 엑셀 다운로드 기능을 제공해야 하는 경우가 굉장히 많은데 최근 기존에 존재하던 엑셀 다운로드 기능이 정상적으로 동작하지 않아 이를 개선한 과정을 공유해 드리고 자 합니다.
문제 상황
평화로웠던 어느 날 갑자기 사내 메신저(슬랙)을 통해 가든의 ‘구매확정’이라는 메뉴에서 엑셀 다운로드 시
504(Gateway Timeout) 상태 코드가 응답으로 반환된다는 신고가 들어왔습니다.

504 Gateway Timeout은 클라이언트에서 서버로 요청을 보낸 뒤 일정 시간 동안 서버에서 응답을 주지 않아 발생하는 오류이기 때문에 타임아웃의 원인을 파악하고자 타임아웃의 로컬 환경에서 엑셀 다운로드 시 걸리는 시간을 측정해 봤습니다.
[측정환경]
- 서버 : Local
- 대상 데이터 개수 : 1,473건
[측정결과]

약 1,000건의 데이터를 다운로드하는데 2분이 넘는 시간이 소요되었습니다 😱
운영 DB와 개발 DB의 스펙 차이와 로그 설정 차이 등으로 인해 실제 운영환경에서는 위 측정 결과보다 나은 성능을 보이겠지만 도저히 그대로 방치할 수 없는 결과가 나왔기 때문에 이를 개선하기로 했습니다.
왜 이렇게 오래걸리는 것인가? - 원인 파악
문제가 되는 부분은 로컬 테스트에서 바로 파악할 수 있었습니다.
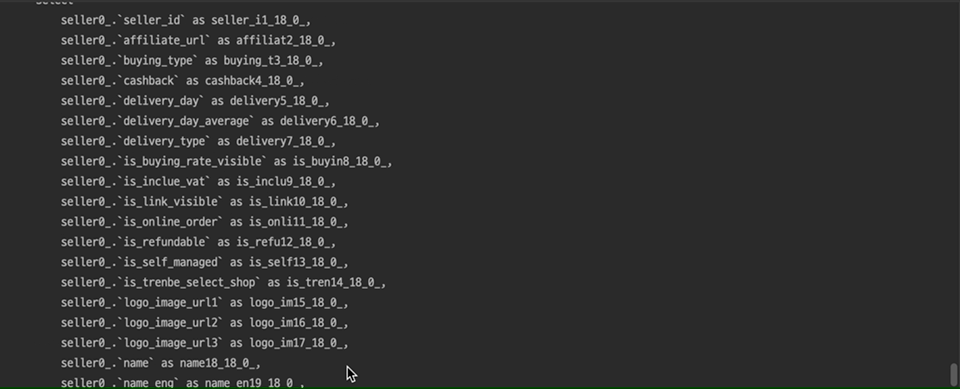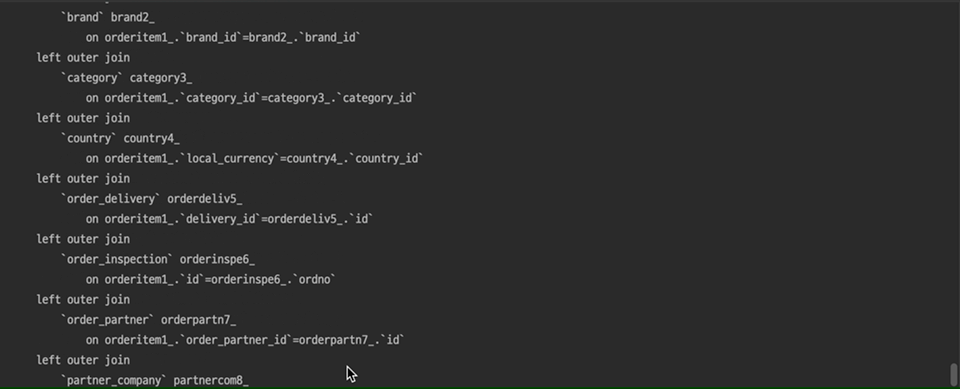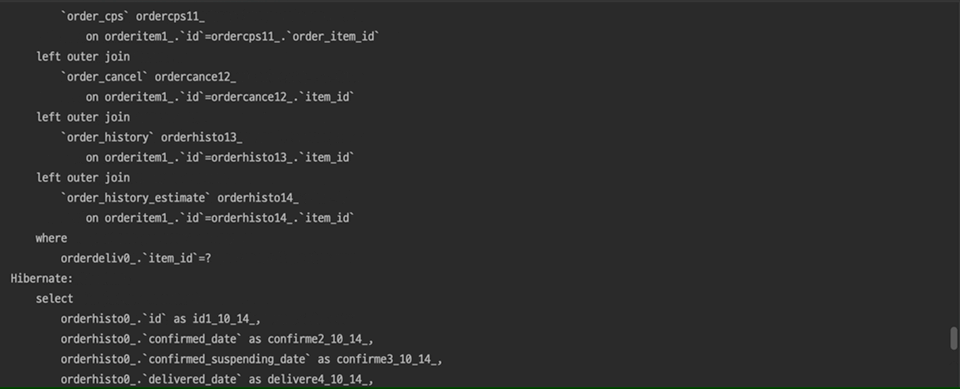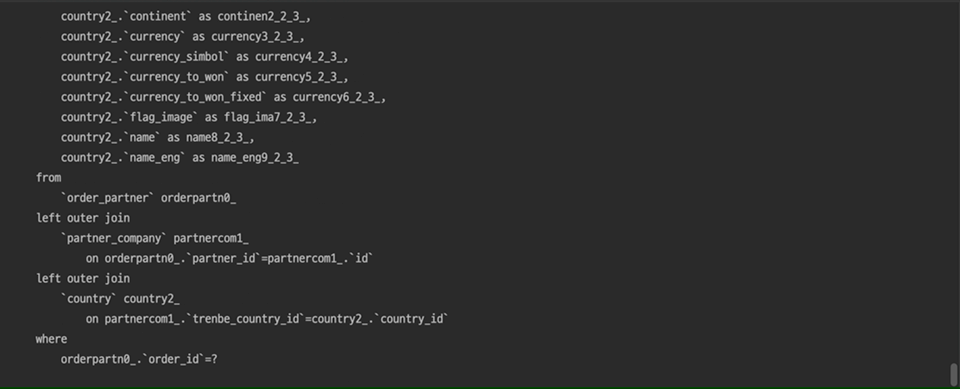
엑셀 다운로드 버튼 클릭 한 번에 무수히 많은 쿼리가 발생하고 있는 모습을 볼 수 있습니다…🥲
문제가 되는 메뉴에서 엑셀 다운로드 시도 시 필요한 데이터를 JpaSpecificationExecutor<T>의 findAll 메소드를 통해 가져오고 있었는데 해당 메소드가 호출될 때마다 N+1 쿼리가 발생했습니다.
public interface OrderItemRepository extends JpaSpecificationExecutor<OrderItem> {
}
@Override
public List<OrderItem> getOrderItemsBy(Specification specification) {
return orderItemRepository.findAll(specification);
}
문제 해결
원인으로 파악된 N+1 문제를 해결하기 위해 두 가지를 변경하게 되었습니다.
첫 번째 변경으로 JpaSpecticifationExecutor<T>제거와 QueryDSL 사용입니다.
문제 해결을 위해 fetchJoin 사용을 고려해야 했었는데 JpaSpecificationExecutor<T>는 개발자가 자유롭게 JPQL을 작성하는데 어려움이 있기 때문입니다.
또한, JpaSpecificationExecutor<T>은 실제로 호출되는 시점에 어떤 쿼리가 나갈지 개발자가 알기 힘들기 때문에 유지 보수에 걸림돌이 된다고 판단했습니다.
두 번째 변경으로 Projection을 사용한 데이터 조회입니다.
다른 주문 관련 메뉴에서도 엑셀 다운로드에 필요한 데이터를 조회하기 위해 동일한 메소드를 호출하고 있었기 때문에 List<OrderItem>을 반환하는 메소드를 구현하는 것이 가장 많은 범위에 걸쳐 개선 효과를 볼 수 있었지만 Projection을 선택한 이유는 다음과 같습니다.
[OrderItem과 관계를 맺고있는 객체가 너무 많이 존재합니다.]
@Entity
public class OrderItem {
...
@ManyToOne
@JoinColumn(name = "orderPartnerId")
private OrderPartner orderPartner;
@OneToOne(cascade = CascadeType.MERGE, mappedBy = "orderItem")
private OrderHistory orderHistory;
@OneToOne(cascade = CascadeType.MERGE, mappedBy = "orderItem")
private OrderHistoryEstimate orderHistoryEstimate;
@OneToOne(cascade = CascadeType.MERGE, mappedBy = "orderItem")
private OrderDeliveryClientGuide orderDeliveryClientGuide;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "orderItem")
private Set<OrderDeliveryClientGuideLog> orderDeliveryClientGuideLogs;
@OneToOne(cascade = CascadeType.ALL, mappedBy = "orderItem")
private OrderCancel orderCancel;
...
}
기존에는 OrderItem 엔티티를 가져와서 엑셀에 필요한 데이터를 채워주었는데, OrderItem은 너무 많은 객체들과 관계를 맺고 있고 그 모든 객체들의 필드가 필요한 게 아니기 때문에 필요한 데이터만 가져와서 채워주기 위해 Projection을 사용했습니다. (위 코드는 OrderItem과 관계를 맺고 있는 객체들의 일부분이며 실제로는 훨씬 더 많은 엔티티 객체들과 연관관계를 맺고 있습니다.)
[OrderItem과 관계를 맺고 있는 많은 객체들이 또 다른 객체들과 관계를 맺고 있습니다.]
@Entity
public class OrderPartner {
@Id
private Long id;
@ManyToOne
@JoinColumn(name = "order_id")
private Order order;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "orderPartner")
private List<OrderItem> orderItems;
@OneToOne
@JoinColumn(name = "partner_id")
private PartnerCompany partnerCompany;
...
}
OrderItem과 관계를 맺고 있는 OrderPartner를 보면 PartnerCompany와 관계를 맺고 있는 것을 볼 수 있습니다.
이 상태로 OrderItem을 조회하게 되면 OrderPartner의 PartnerCompany에 값을 채워주기 위해 N 개의 쿼리가 더 발생하게 됩니다.
이를 해결하려면 OrderItem을 Root로 객체들을 탐색하며 여러 Depth에 걸쳐 관계를 가진 모든 객체들을 찾아내 fetchJoin을 걸어주어야 하는데 이는 너무 많은 불필요한 조인을 유발합니다.
QueryDSL을 사용해 아래와 같이 엑셀 다운로드에 필요한 데이터만을 조회하는 새로운 메소드를 작성해 호출해 보니 드디어 N+1 문제가 해결되었습니다.
@Override
public List<OrderItemExcelDownloadDto>findOrderItemExcelDownloadDtosBySearchCondition(OrderItemExcelDownloadSearchCondition searchCondition) {
return jpaQueryFactory
.select(Projections.bean(OrderItemExcelDownloadDto.class,
orderItem.id.as("orderItemId"),
orderItem.name.as("orderItemName"),
orderItem.goodsno,
...))
.from(orderItem)
.join(orderItem.orderPartner, orderPartner)
.join(orderPartner.order, order)
...
.where(expression(searchCondition))
.orderBy(orderItem.id.desc())
.fetch();
}
N+1 문제가 해결되어 처음 시도했던 동일한 환경과 데이터로 다시 속도를 측정해 봤습니다.
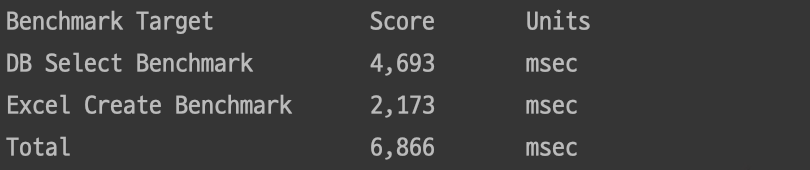
2분 40초에서 6초로 다운로드 소요 시간이 감소했습니다.
(N+1 문제 해결 후부터는 DB 조회 시간과 엑셀 다운로드 시간을 분리해서 측정했습니다.)
N+1 문제 해결로 많은 개선이 이루어지긴 했지만 만족스럽지 못한 부분이 있습니다.
DB에서 데이터를 조회하는 시간은 조인이 걸려있는 테이블의 개수가 너무 많아 어쩔 수 없다지만 겨우 1,000건 정도의 데이터를 가지고 엑셀을 생성하는 데 2초나 걸렸습니다.
만약 데이터의 수가 몇 만 건 혹은 몇 십만 건이 되었을 경우에도 원활하게 다운로드가 가능할 것인가에 대해 자신 있게 YES라고 대답할 수 있는 결과는 아니었습니다.
이걸 어떻게 더 개선할 수 없을까 고민하며 코드를 살펴보다 기존에 사용하고 있던 엑셀 다운로드 유틸에 작성되어 있는 Apache POI 라이브러리의 Workbook 구현체가 XSFFWorkbook으로 되어있는 것을 발견했습니다.
public static <T> void orderDownload(HttpServletResponse response, List<T> data, String fileName, Integer useType) {
Workbook workbook = new XSSFWorkbook();
...
}
XSFFWorkbook은 데이터를 메모리에 모두 올려놓고 쓰기 작업을 수행하기 때문에 굉장히 많은 메모리 공간을 필요로 하고 데이터가 많을 경우 OOM(Out Of Memory)가 발생할 확률이 높습니다.
그러면 XSFFWorkbook이 아닌 어떤 구현체를 사용해야 할까요? 바로 SXSSFWorkbook입니다.
아래 화면은 Apache의 POI 라이브러리에 대한 공식 문서 일부입니다.

SXSSF라는 것에 대해 소개하는 부분이 있는데, 밑줄 친 부분을 보면 아래와 같이 설명하고 있습니다.
SXSSF is an API-compatible streaming extension of XSSF to be used when very large spreadsheets have to be produced, and heap space is limited.
SXSSF는 XSSF를 확장한 API로 힙 공간이 제한적이고 매우 큰 스프레드시트를 생성해야 할 때 사용된다.
이제 XSSF 대신 SXSSF를 사용해야 쓰기 작업 시 유리하다는 것을 알았으니 XSSFWorkbook을 SXSSFWorkbook으로 변경한 다음 재측정해 봤습니다.
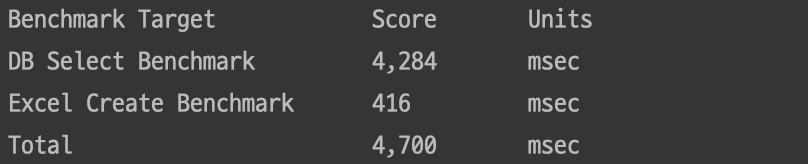
2초에서 400밀리 초로 엑셀을 생성하는 시간이 줄어들었습니다.
어떻게 이런 차이가 발생한 것일까요?
그 이유는 SXSSFWorkbook이 “BigGridDemo”라는 전략을 구현하고 있기 때문입니다.
위 전략을 구현한 SXSSFWorkbook은 설정된 WINDOW_SIZE(default=100)만큼만 데이터를 메모리에 올려 작업을 수행하기 때문에 모든 데이터를 메모리에 올린 뒤 작업을 수행하는
XSSFWorkbook에 비해 적은 메모리 공간을 사용해 효율적으로 쓰기 작업을 수행할 수 있게 됩니다.
Workbook 구현체까지 변경한 뒤 처음 2분 40초와 비교하면 97%정도의 개선이 이루어졌습니다.
사실 2초 정도의 차이로는 크게 개선이 이루어진 것으로 보이지 않을 수 있습니다.
하지만 위 결과는 천 개 정도의 적은 데이터로 측정한 것이고 실제로 데이터 수가 늘어날수록 차이가 커지게 됩니다.
데이터가 많아질수록 차이가 커지는 것을 보기 위해 30,000개의 데이터를 가지고 구현체가 XSSFWorkbook 일 때와 SXSSFWorkbook 일 때를 비교해 다시 측정을 해보겠습니다.
[XSFFWorkbook]

[SXSFFWorkbook]

무려 16초의 차이가 발생하는 것을 볼 수 있습니다.
여기까지 N+1 문제 해결과 더불어 엑셀을 생성하는 시간까지 개선하는 과정을 보여드렸습니다.
현재 가든에서는 백오피스의 많은 메뉴들을 관리하고 있고 대부분의 메뉴에서 엑셀 다운로드 기능을 제공하고 있기 때문에 아직 더 많은 개선이 필요하다고 생각합니다.
마치며
JPA를 사용해 엑셀 다운로드에 필요한 데이터를 조회하는 경우 Projection을 통해 필요한 데이터만을 조회하는 것을 고려해 보면 좋을 것 같습니다.
DB 조회 속도 개선도 중요하지만 데이터 수가 많아질수록 서버에서 엑셀을 생성하는데 많은 시간이 소요되기 때문에 Apache POI 라이브러리를 사용하는 경우 Workbook의 구현체로 SXSSFWorkbook을 사용하는 것이 좋습니다.